


Whether you are new to GraphQL or already an old hat in the game, you've undoubtedly come across Relay. Relay was designed and developed in response to the real-world needs that arose after Facebook released GraphQL for companywide adoption. Simply put, Relay solves the problems you've undoubtedly faced yourself.
To be fair, Relay does need a little bit of setup, and the server needs to support some assumptions that Relay will make of it. Regarding the assumptions, well, GraphCMS supports Relay out of the box! Nothing special is needed, you can use Relay today.
Regarding the boilerplate, well, that's what this post is intended to help solve. By far, the simplest way to get started with Relay would be using an existing web framework. We are somewhat bullish on NextjS here at GraphCMS, and they have a Relay framework that we've based our example on. You can skip to the cloning step directly right here.
What is RelayAnchor
Relay is ultimately composed of a few "primitives" or building blocks that assist with the adoption of GraphQL in your project.
EnvironmentAnchor
First, Relay includes an Environment constructor that handles the injection of the network layer and store throughout your app.
Network LayerAnchor
The network layer can be thought of as Fetch on steroids. It allows you to define the method in which you'll query your GraphQL endpoint throughout the application. If you need to define auth tokens or any other type of network settings, this is the place to do it. By default, a sensible local cache is also enabled.
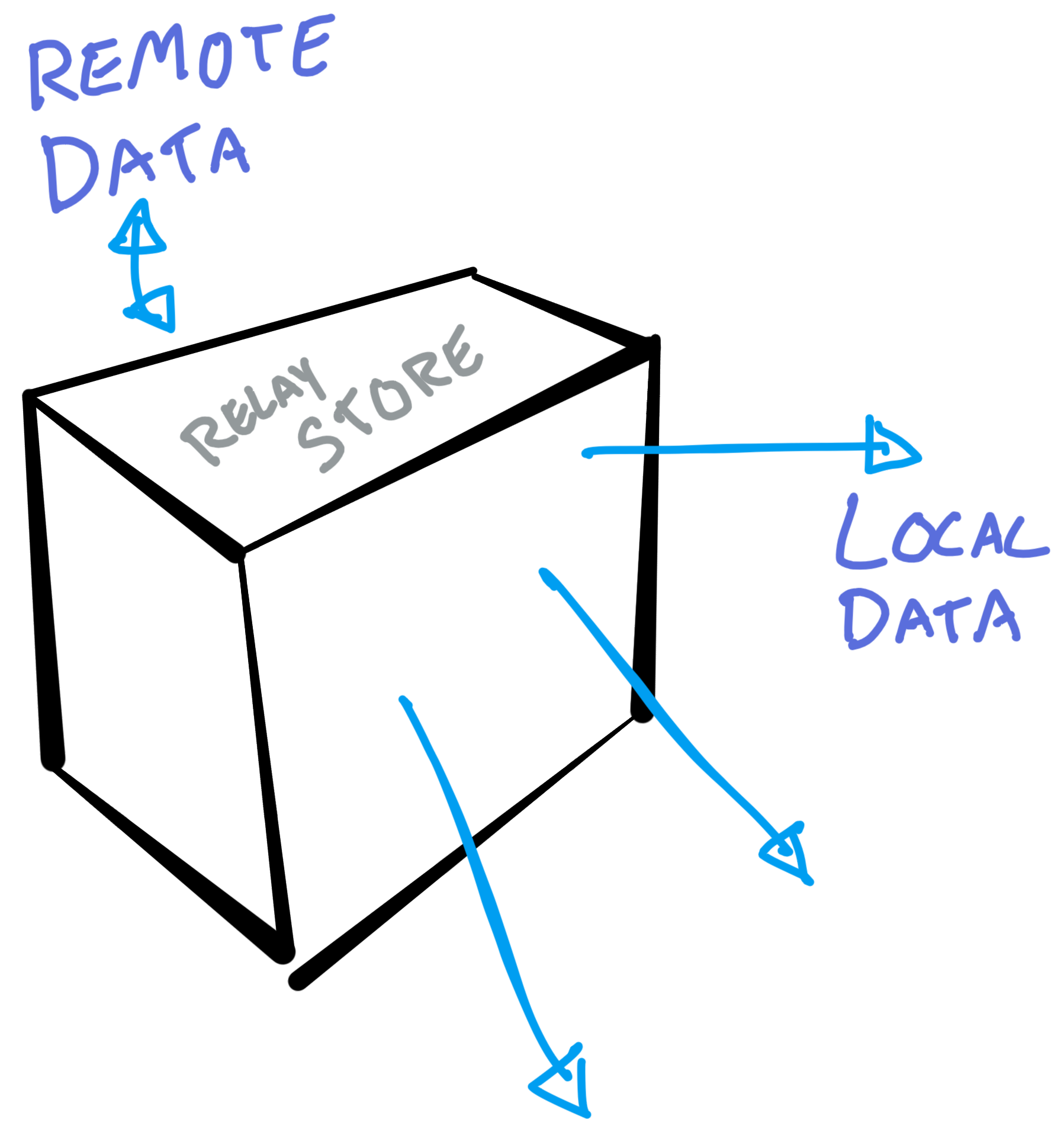
Relay StoreAnchor
The store is a type of local data "state manager." This allows you to arbitrarily fetch content throughout your application "after" it has been queried for by Relay, and will watch for updates. This lets you break out of the hierarchical data-dependency chain that composition can sometimes force on your app. Typically the parent needs to know about which data the child needs so that it can wire those dependencies down the composed stack. With the store, you can sort of pick bits of data from the store by key reference and drop them somewhere else in your application and they'll only be updated when the data is there.
Composition HOCsAnchor
This feature is where some of the more practical benefits of Relay come into their own. Relay comes with a series of Higher-Order Components that let you handle behavior such as pagination, watching/re-fetching, and Fragment management.
We've linked the documentation to each of the respective components, but let's look at the Fragment Container (their term for the HOC). What makes this so special is that the individual component is allowed to declare the data it will be needing, and Relay guarantees the component won't load until the data requested is present! That's a major safety feature! For those who've worked with Gatsby, this is quite similar to how exporting fragments from components works, except that with Relay, you can pass arguments to the components which let you work with variables. That is a substantial developer experience boost.
CLI ToolingAnchor
To achieve these benefits listed above, Relay needs to know a few things about your project. First, it needs to know about your Schema, then it needs to know about all the queries you are using and all the fragments that individual components have declared. It then needs to optimize all of those so that at runtime, it can make clean and succinct queries (or mutations) to your server.
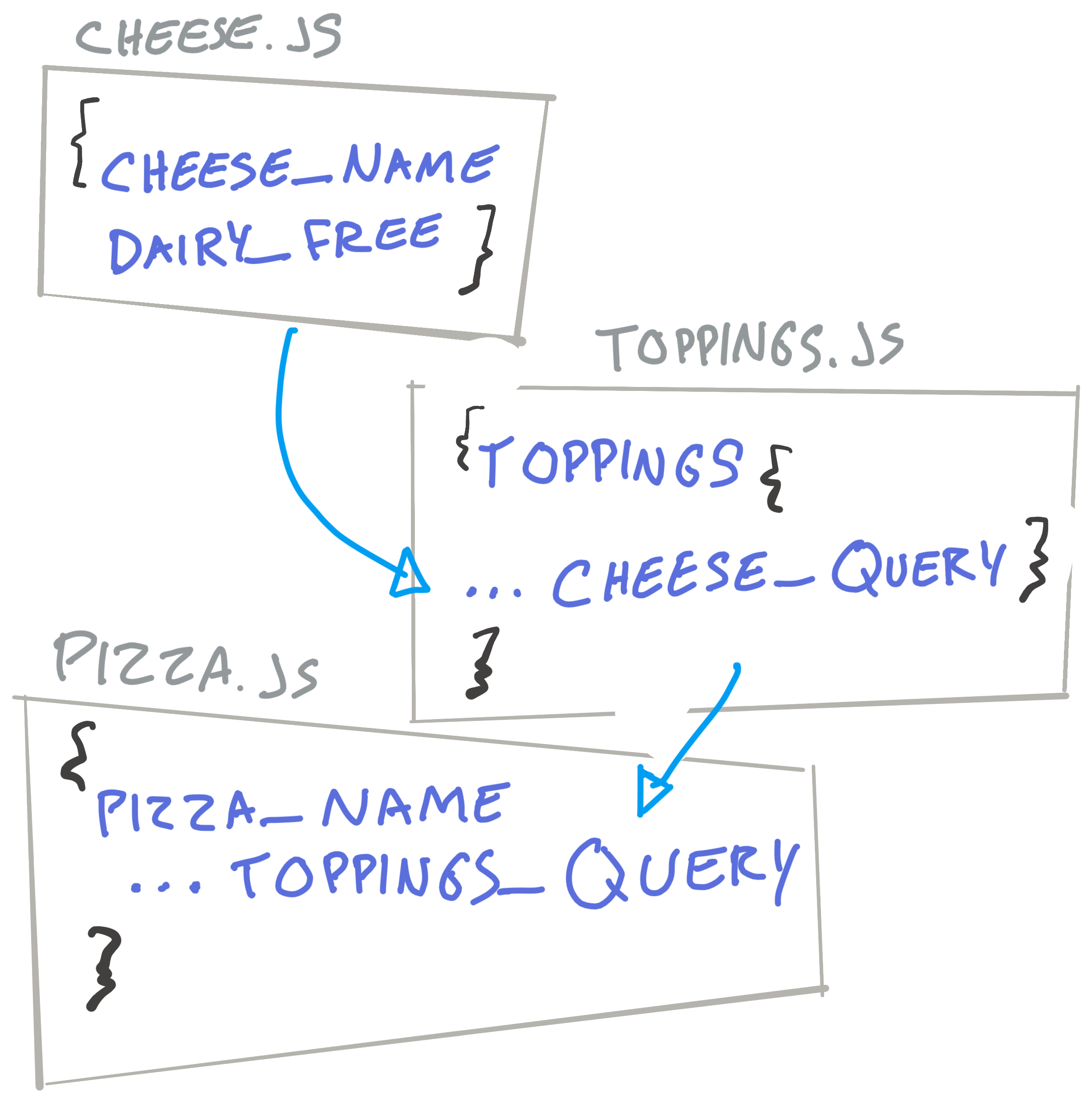
To do all of that, Relay has some built-in tooling for downloading your schema and for pre-compiling your queries. To assist the tooling Relay does expect a consistent naming convention that it will warn you about if you don't adhere. This generally follows the pattern of "Filename" followed by the expected property you assign to the response. In the case of the linked example, we'd see a Fragment named something like fragment Pizza_pizza, which corresponds to the name of the file Pizza and the property I assign the response to, pizza.
SummaryAnchor
Obviously, there's much more that one could learn about Relay, and I encourage you to do so. Whether you are wanting to embrace full type-safety through your code and data dependencies, or are simply trying to avoid prop-drilling data through layers of nested composition (particularly dangerous in a team setting) - Relay will help you solve all of those architecture pieces and more.
Pagination is one area in particular where users get into a lot of trouble when they first adopt GraphQL. Relay will take a series of filters that define what a page is and then return helpers to indicate a loading status, whether or not there are more elements to fetch and the ability to define directionality in the fetching.
GraphCMS, for its part, implements the required node interface, pagination filters, and generated connection types for you already so you can simply plug any GraphCMS API in to a Relay project, run the tooling to introspect the schema, and be ready to work.
Checkout the repo and let us know what you think! Demo is live here.

