


In this example, I will demonstrate how to build a Low-Code CSV batch importer for GraphCMS. This can be helpful to teams working with low-code tools because it is specifically a “batch” importer, which many low-code tools don’t support and uses a bit of a workaround with GCMS to actually run the batch import by creating an import relation.
A good headless CMS is marked by a good API. GraphCMS has a great API. A CMS offering an API interface should lend itself to a smooth data import and export operation. Fortunately, again, GraphCMS offers great support for this. Whether you are using the management and content APIs in tandem to model and import your content, or you are using just the content APIs to import and export your content, the API is able to support whatever pattern and tooling you’ve chosen.
Picking the right tool, however, can be more complex. GraphQL APIs can be accessed with any number of languages from JavaScript to Java. Writing a small library of import utilities is a straightforward task.
If you know how to code.
Why Create a Low-code Importer?Anchor
While there’s great documentation on how to programmatically import content with custom scripting, not everyone knows how to code. Being able to leverage a low-code environment where we abstract as much of the code away as possible, enables content editors and creators to help with importing their content without needing additional dev resources.
And as the editors and creators are the ones who understand the content best, it becomes an invaluable opportunity to catch any import errors at the time of import, and not later in staging, or worse, production.
What is a Low-code Tool?Anchor
A low-code tool, sometimes referred to as a no-code tool, is a tool that abstracts the conditional logic and function calls that programmers work with when building apps and scripts, into drag-and-drop utilities and flow diagrams that are more approachable to a larger audience.
And don’t make the mistake to think low-code is simply for those who haven’t learned how to code yet. Low-code is an $11 billion market with more enterprises embracing low-code solutions every day. The visual auditing process and smaller surface area for bugs make for a very compelling use case for companies of all shapes and sizes.
Our Low-code Tooling RequirementsAnchor
Solving the problem of data importing will require a special category of low-code tooling, however. We’ll need a tool capable of mapping large amounts of data to tables, ideally with pagination, and something that works well with protected environments, i.e., we can use secrets or make sure that only those we trust are using the application.
We refine our requirements even further because GraphCMS doesn’t have any REST endpoints, and so we need a tool that allows us to write to our API where we can customize the information that is sent, namely, writing a custom query. We won’t be able to keep our hands completely clean of code, but we’ll keep it to a minimum, I promise!
There are a few options that are capable of handling this task, some of them are quick to set up and suit themselves to faster onboarding like Bubble.io, or Retool, whereas others are focused on a higher-touch onboarding process like OutSystems and Mendix. One could even configure Powerapps from Microsoft to accomplish much of this workflow, as well!
Let us know if that’s something you’d like to see. If you are looking for an open-source option, ToolJet may be something for you.
Introduction to RetoolAnchor
The tool we’ll be using is Retool, for one very particular reason, and that is excellent support for GraphQL! The platform lends itself to fast onboarding, the ability to self-host for sensitive contexts, and a clean interface that is simple to reason about.
TutorialAnchor
What are we Going to Build?Anchor
We’ll make the assumption that our content team needs to import a number of CSVs to our model, so we’ll allow for uploading new CSVs to import into the future. We’ll need the following components:
An ability to upload a CSV.
An ability to make some bulk edits if needed.
An ability to rename columns.
An ability to paginate through the CSV so we don’t go over our API limits.
What Does our Dataset Look Like?Anchor
The dataset we are going to work with is a contrived example of educational institutions (academies, colleges, universities) with faculty and courses. Our rough database diagram looks like this:
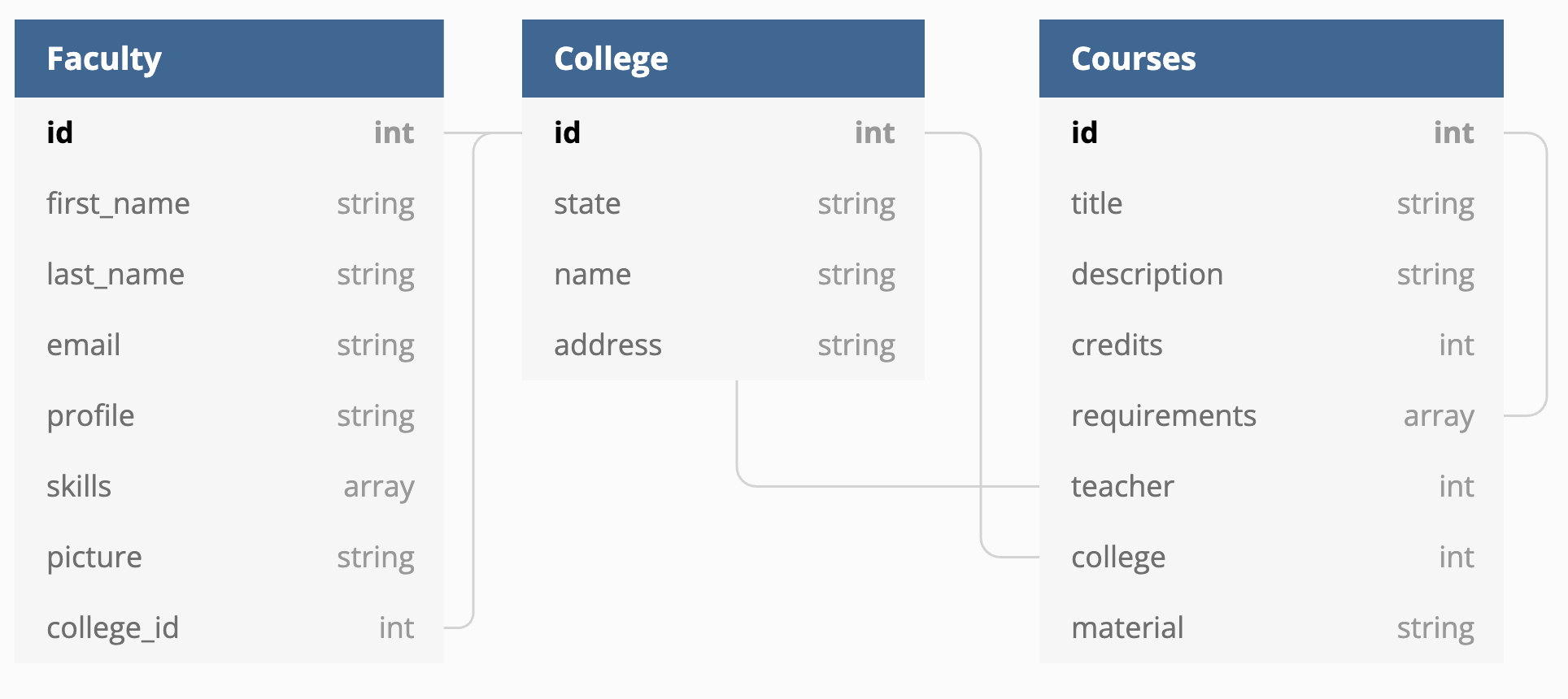
Our target graph structure will ideally be a little more normalized at the end. Note, GraphCMS abstracts away the join tables (i.e. Faculty_skills – so we won’t be creating this model by hand.)
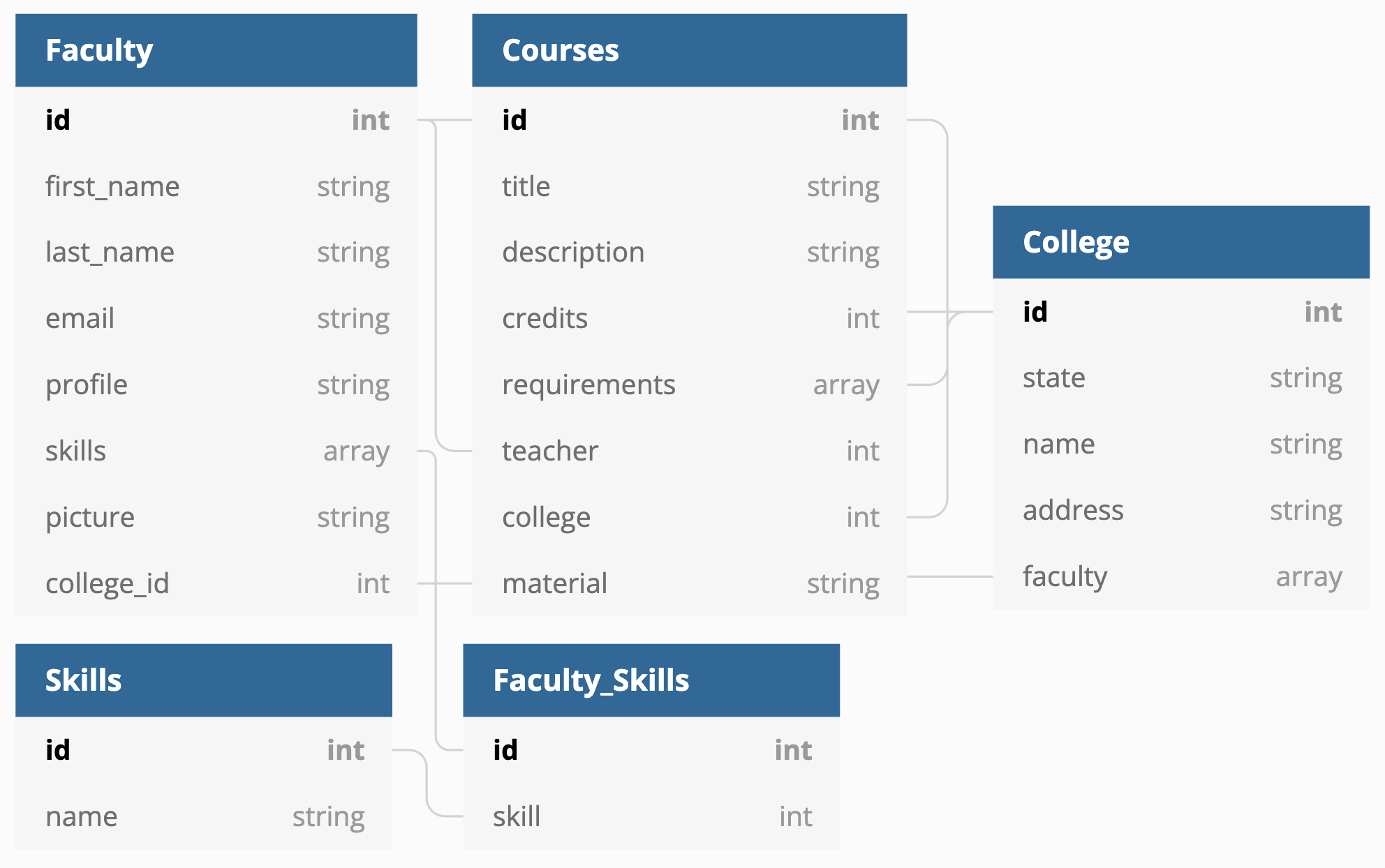
The Source ContentAnchor
Let’s preview our source content to see what we have to work with. Since this tutorial is about importing CSVs, that’s the structure of our data.
CoursesAnchor
1,Synergistic static database,"In congue. Etiam justo. Etiam ...",5,"[{""id"":15},{""id"":636},{""id"":782},{""id"":553}]",134,6,UtVolutpat.tiff
FacultyAnchor
1,Fair,Ryder,fryder0@java.com,"Morbi porttitor lorem id ligula...","[{""title"":""Japanese Language Proficiency Test"",""years"":30},{""title"":""Program Evaluation"",""years"":22}]",http://dummyimage.com/x.png/ff4444/ffffff,5
CollegesAnchor
1,California,California Maëlla Academy,0131 Weeping Birch Court
Create a CSV Read Utility in RetoolAnchor
Our first process will be to create a utility in Retool to upload and read a CSV. Creating an account in Retool is a matter of signing up for the service and we won’t go over that in detail here. Once you have a Retool application open and you are ready to edit, we’ll begin by deleting the default table provided so that we have a clean screen.
Start by adding a File Button, and a Table from the components sidebar.
You can see how this looks in the following image.

I’ll rename my components to “upload” and “recordBrowser” respectively. You can do this in the inspector.
Alright, we have a minimal layout already taking shape! Let’s support parsing the values from our upload behavior, you might have already tried clicking on the File Button and seen that it already lets us browse our filesystem. Go ahead and find a CSV you’d like to work with, you can find the sample CSVs for this tutorial linked at the bottom of this page. We’ll use the “courses.csv” as an example.
Iterating Over the CSVAnchor
Select the table component and navigate to the inspector panel, here we can see the “Data” column, this is where we’ll add the data that gets looped over. Replace any existing values with the following dynamic values.

In Retool, the {{...}} syntax means we are using a dynamic variable. We are grabbing the component of our Upload Button (that we renamed to ‘upload’) and grabbing the parsedValue, where the first element in the parsedValue array is the actual data. I’m providing an “or” operator “||” to tell the component, if you don’t see any data, then you can use an empty array so that the interface doesn’t show us errors.
You should now see your data in the table!
Support Editable ContentAnchor
Out of the box, we get pagination and filters on the table component. We’ll leverage those later. Sometimes, when we are transforming content from one system to another, we may want to take advantage of some data cleaning. We can define one or more of these columns as “editable”.
Begin by selecting the table where our data is present. In the Inspector, we’ll scroll down to the columns section where we can see all the columns our CSV has. Click on the top-level “Editable” checkbox which will make each cell editable by default. Once you’ve done this once, you won’t need to do this again as long as the schema for the CSV is the same, if you use additional CSVs, you’ll need to do this for each CSV. If you want to do this on only a limited subset of columns, you can.

Creating a Key Mapper in RetoolAnchor
Many times the column names of your CSV don’t match up to the new names you want to import your data into. Let’s make a transformer utility that will let us convert our data.
Drag a “ListView” component onto the canvas.
We’ll rename this component to ‘keyChange’. We’ll need an additional feature of Retool to unlock our full potential here.
First, we’ll create a piece of temporary state. You’ll find that in the right-hand sidebar. If that’s hidden, you can show it by clicking on the far-left side, here.

Make a new state called ‘keyMapper’. We want to populate this key/value store with the column names from our CSV. To do this, we’ll define an interaction after we upload a CSV. Selecting the upload button, we’ll define the event to watch for as the “parse” event of the file being uploaded.
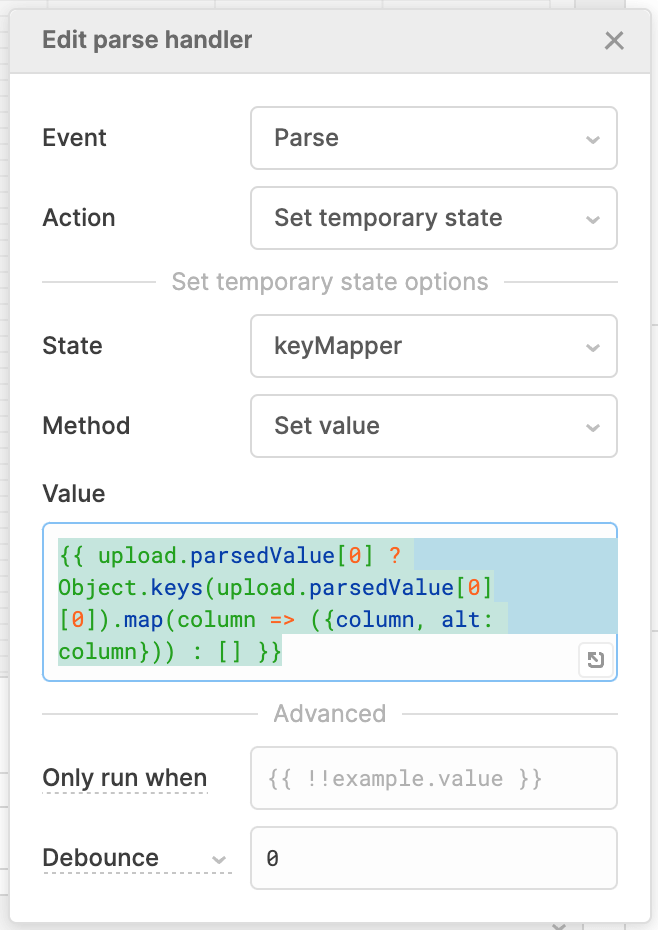
We’ll tell the action to be setting the temporary state of our keyMapper, setting the value defined in our little bit of code.
Our code takes the parsed value, grabs the keys (or column names), and creates an object of the column name and a temporary copy of the same column name called alt. This ends up with a list of objects such as [{column: “name”, alt: “name”},{column: “location”, alt: “location”}].
With our state set up as a key/value pair of our column names, we need to update our keyChange component to run over these values. We do this by telling the list component how many rows to expect, followed by what to do for each row.
Telling the component how many rows is straightforward.
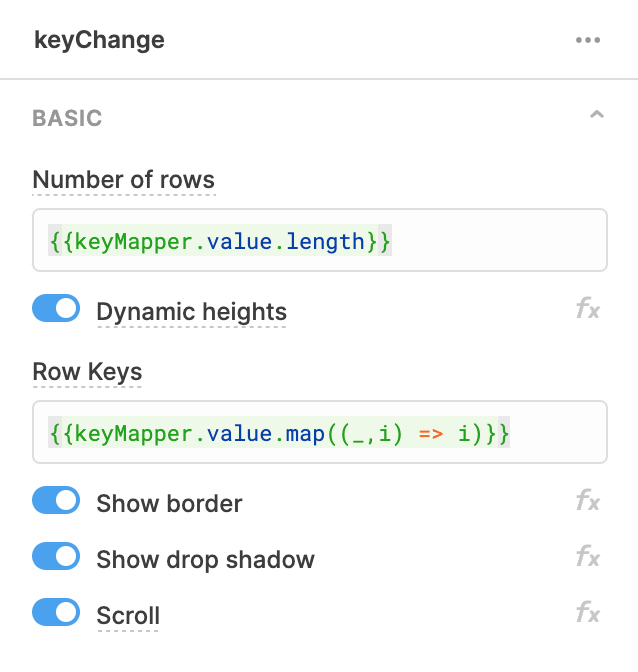
The number of rows is a property called “length” of the keyMapper value. Again, this is a dynamic value so we access this by using the {{}} pairing. Row keys is a performance optimization that allows Retool to keep track of the addition/removal of rows.
Mapping/Row Keys ExplainedAnchor
We can synthesize some values here by mapping (looping) over the values of our key/value store and returning the index/position (i) of that list. While this might look confusing, we are simply turning a list such as [a,b,c] into a list of [0,1,2] which lets us force a unique value. I might have a list of [a,a,b] which would not have only unique values, but it will always be [0,1,2,...] for every item I have.
Inside of the list component we drag an input component, which lets us provide a temporary value and a label.
The configuration for this component is as follows.
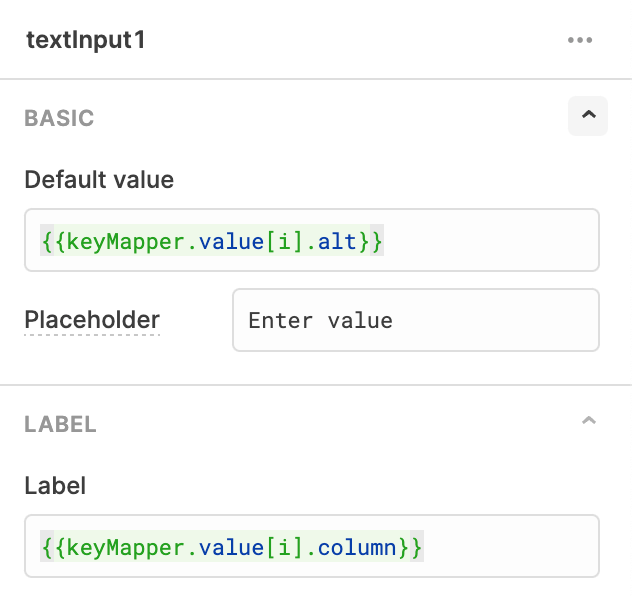
We reference the value of the state we filled with column name pairings. We then reference the “i” value (position in the list) and grab the alt value for our text input, and the column value for the label. This gives us an end effect of a list of editable values!

Importing to GraphCMSAnchor
This tutorial will not cover creating a schema in GraphCMS. We’ll assume you already have that experience, and if not, there’s lots of content available for just that topic! We’ll consider the normalized model from above.
Our legacy data system we are importing from, the source of our CSV values, includes the legacy identifiers (IDs) which we’ll maintain for now to help us track relationships across systems.
When we model the course, we’ll persist the ID to an API-only value called “course_id” which will allow us to make those relationship connections at a later time.
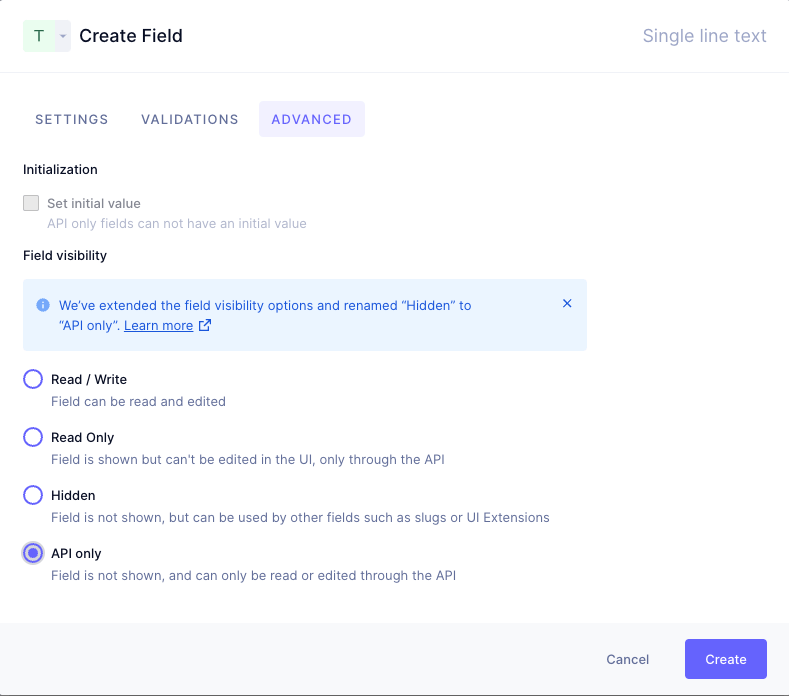
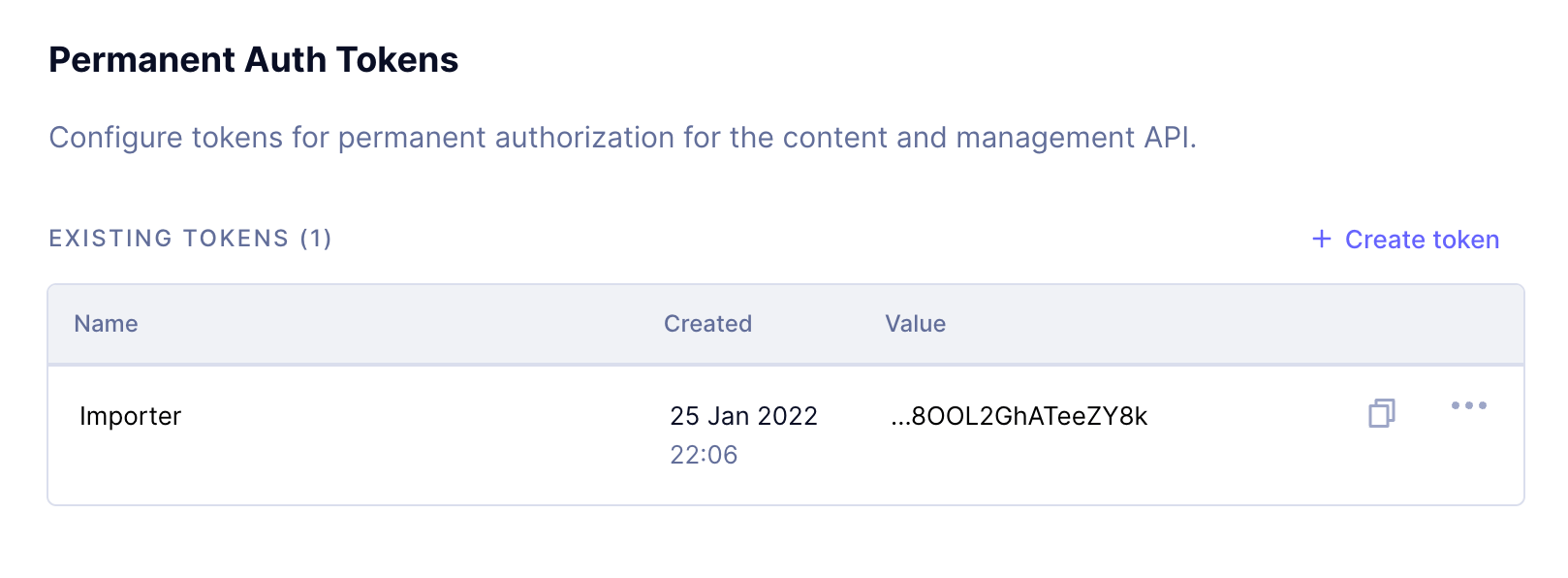
Generating Import TokenAnchor
To track who is importing what into our system, we’ll create a specialized import token that we can revoke later if need be. Creating permanent auth tokens is not part of this tutorial, but you can read more about tokens here.
Order of ImportAnchor
An important step in importing content to any relational system is to consider your order of inputs. With GraphCMS, it’s possible to import highly nested data structures where one could import a class, teacher, and college in one step. The reality is, this will depend a lot on the confidence level you have in the matching of your source content to your end form. Working with CSVs tends to be a much flatter data structure than one would typically use to import into a relational database as a nested import.
We’ll be importing single “sets” of data with our approach, starting with the least interdependent and working outwards to the most interdependent. This is where persisting our original identifiers will come in very useful.
Defining the Shape of the MutationAnchor
We’ll use the GraphCMS interface to design our import mutation. To begin, we’ll work with the College model, importing Name, State, Address, and college_id.
The sampling from our CSV in Retool shows the following original data source.
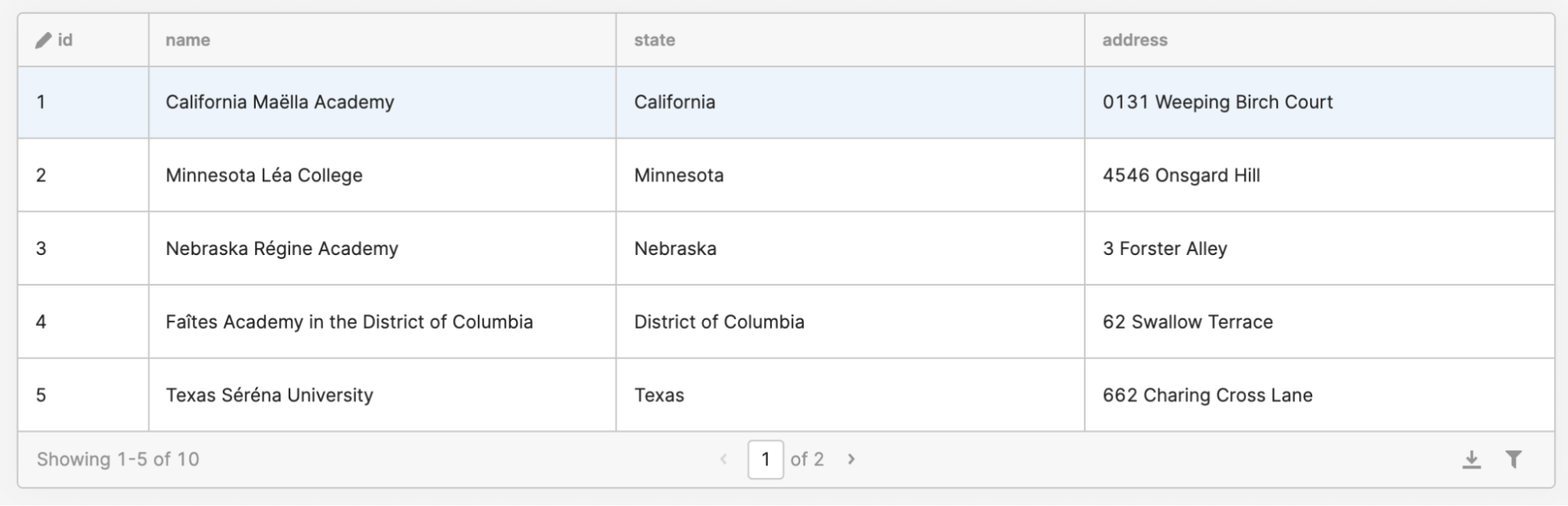
As we go to define our mutation, however, we’ll notice a small problem - GraphCMS doesn’t currently have a way to create or upsert many records at once – but there’s a trick! Like any trick, there’s a catch, and the catch is there’s a risk of creating duplicate content, but if we set the right fields with unique constraints, we can avoid that potential issue. We’ll use our legacy IDs as the unique data sources in our system.
The trick we’ll be employing is creating multiple entries for a related item. While our goal is to import multiple colleges, we’ll actually be creating an “import” teacher and creating multiple college associations for that teacher.
To handle the edge case where our teacher would be recreated and error, we will be using an upsert statement which will let us use the same teacher for the different pages of our import.
Our mutation looks like the following:
mutation ImportColleges($data: [CollegeCreateInput!]) {upsertTeacher(where:{email: "IMPORTER@IMPORTER.IMPORTER"},upsert: {update: {colleges: {create: $data}},create: {firstName: "IMPORTER",lastName: "IMPORTER",email: "IMPORTER@IMPORTER.IMPORTER"colleges: {create: $data}}}) {id}}
Our variables will be a payload in the shape of:
"data": [{"name": "","state": "","address": "","collegeId": ""}], …}
We’ll test the mutation in the editor to see if it works as expected. Create some fake values for the variable payload and run the mutation. Set your environment to your importer token to be sure you are testing with the correct permission scope.
If it worked correctly, you’ll have created a new teacher and college. Let’s delete those as we move back to Retool.
Creating the Import Resource QueryAnchor
In Retool, saved queries (SQL, GraphQL, etc) are defined as Resource queries. We can create those from the bottom panel of the main Retool editing application. We’ll choose “Resource query”, followed by selecting a GraphQL query. One of the reasons we’ve chosen Retool for this demo is the excellent first-party support for GraphQL.
If we provide our mutation from GraphCMS, and the API endpoint, we’ll see that the editor auto-populates the variables needed for “data” – this is where we’ll do our transformation that maps the table, transforms with our key mapper utility, and ultimately provides the payload we tested within GraphCMS.
You’ll want to provide your import auth token under the headers below.

We’re almost there!
Paginating and TransformingAnchor
The table we are working with has sliced views of our total data set. GraphCMS itself has a batch limit of 1000 operations. Our table, with its default limit of five rows, is comfortably within those limits. But the table slice view is customizable per the low-code mantra.
What we want to affect is the ability to grab the current slice of data from the table, transform the column names, according to our key remapper widget, and batch import those into GraphCMS.
We’ll create one more component which helps us visualize the data we will be importing into GraphCMS. We’ll add a JSON viewer below our table. This will let us view the transformed data. The last box is our JSON viewer. We can define the content that shows up in the inspector.
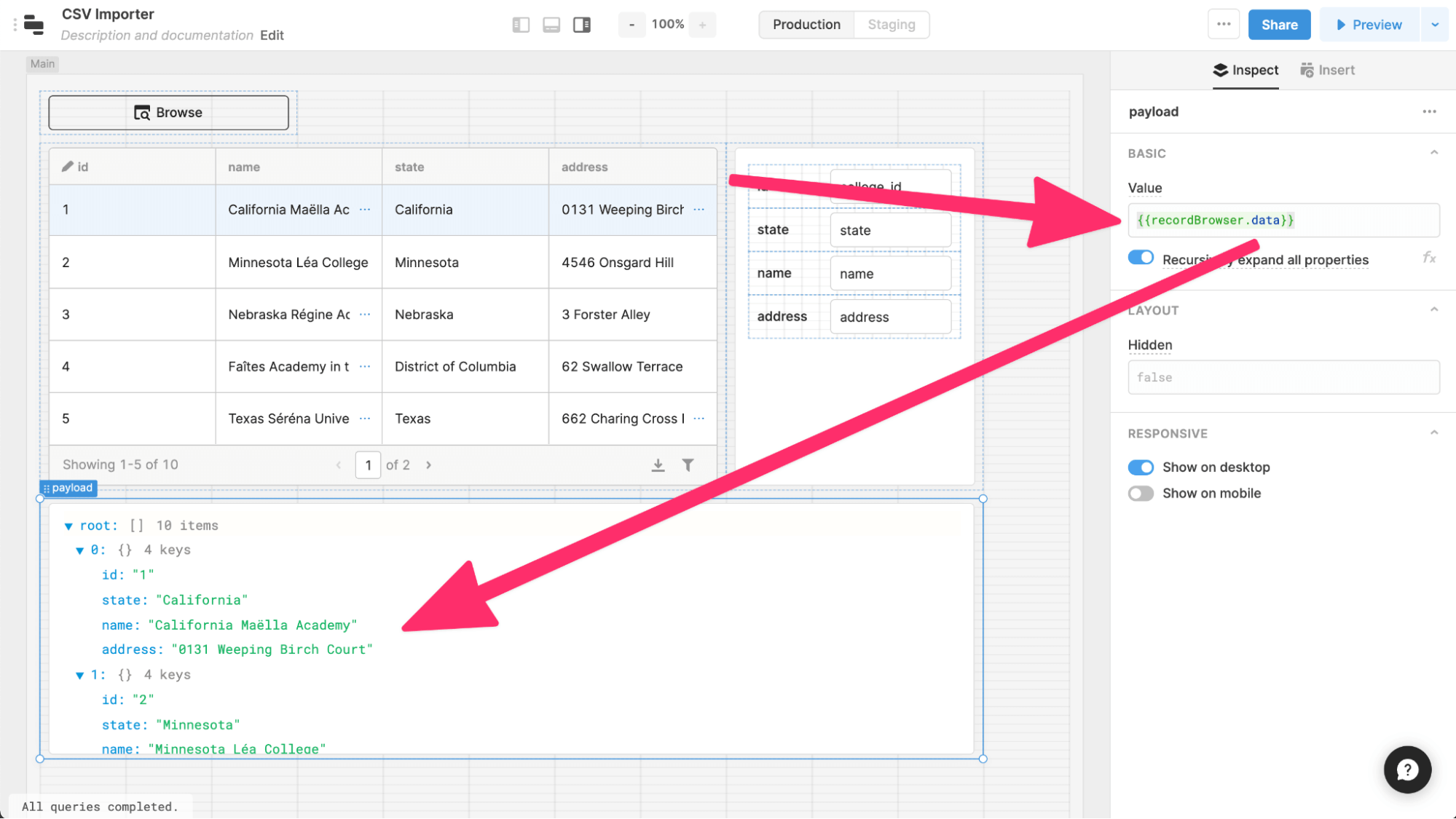
Note that the count at our root of the JSON browser is ten, but our slice of data from the table is five.
This bit of code here in the {{recordBrowser.data}} is where we’ll run our transformation and pagination logic. This will be the most complex bit of code we need to write, but once this exists, this logic will work for all of the sheets we want to import, and this will work across APIs, too!
According to the docs, these execute as something known as an immediately invoked function expression, IIFE, which means, we can also write pure JavaScript in here!
Let’s look at our code dump section by section, skip to the last section to see the complete statement.
Here’s the complete view of our script, you can copy the code at the end of this explanation.

Lines 1 and 31 are the open and close of our IFFE block. Lines 2 through 30 are vanilla JavaScript.
Lines 3-6 grab the number of rows and the current page number of our table component.
Lines 8-9 use the pagination settings to slice the current data (a set of five records).
Lines 11-15 create a dictionary from our key mapper component. This is a useful tool for us to get a direct mapping between the old column name and the new column name.
Lines 17-27 transform our code, but we’ll break it down into smaller steps.
Line 18 loops through each row of the slice of data (five loops).
Line 19 grabs the keys (or column names) from the original object, then uses that list of names to create a new object (our reduce method) inserting a new key on the object using the name we set up in our dictionary.
Line 21 provides a filter that lets us skip any column we prepend with “” - you can remove this logic, but it’s helpful to pull columns off the data if you don’t intend to import that content.
{{(()=>{// The start of the current page in the table viewerconst pageStart = recordBrowser.paginationOffset// The end of the current page in the table viewerconst pageEnd = recordBrowser.paginationOffset + recordBrowser.pageSize// The current view of the tableconst currentView = recordBrowser.data.slice(pageStart,pageEnd)// Template for the shape of the new object// Transform KeyMapper into a dictionary in shape of {oldKey1: newKey1, oldKey2: newKey2}const dict = keyMapper.value.reduce((collect,curr) => {collect[curr.column] = curr.altreturn collect},{})// Transform current Table view with new column names.const payload = currentView.map((row) => {return Object.keys(row).reduce((collection, current) => {// Filter all keys prepended with __if (dict[current].slice(0,2) !== "__") {// Transform object with new column name.collection[dict[current]] = row[current]}return collection}, {})})return payload})()}}
Tip: A better solution would be to use a CSV manipulation tool to delete columns you don’t intend to use and to control any large-scale data transforms before this step.
Ok, so that’s now exactly low-code, but that’s as complex as it gets! And this logic is reusable for all the other CSV’s we’d import.
Now we can view the transformed content in our JSON browser and navigate between the pages.
Importing the Content to GraphCMSAnchor
With our data transformed, we need three last steps. Telling our mutation query which data to pass as the data variable, and providing a button to run the mutation.
Editing our resource query, we can simply tell the variable to grab our value from the JSON browser.

Note, I’ve named my JSON browser “payload”.
Lastly, we’ll create a button on the table component and tell it to execute the importColleges Query (you’ll need to change the query you are executing for each CSV you import, but only the mutation shape changes.

Run the import!
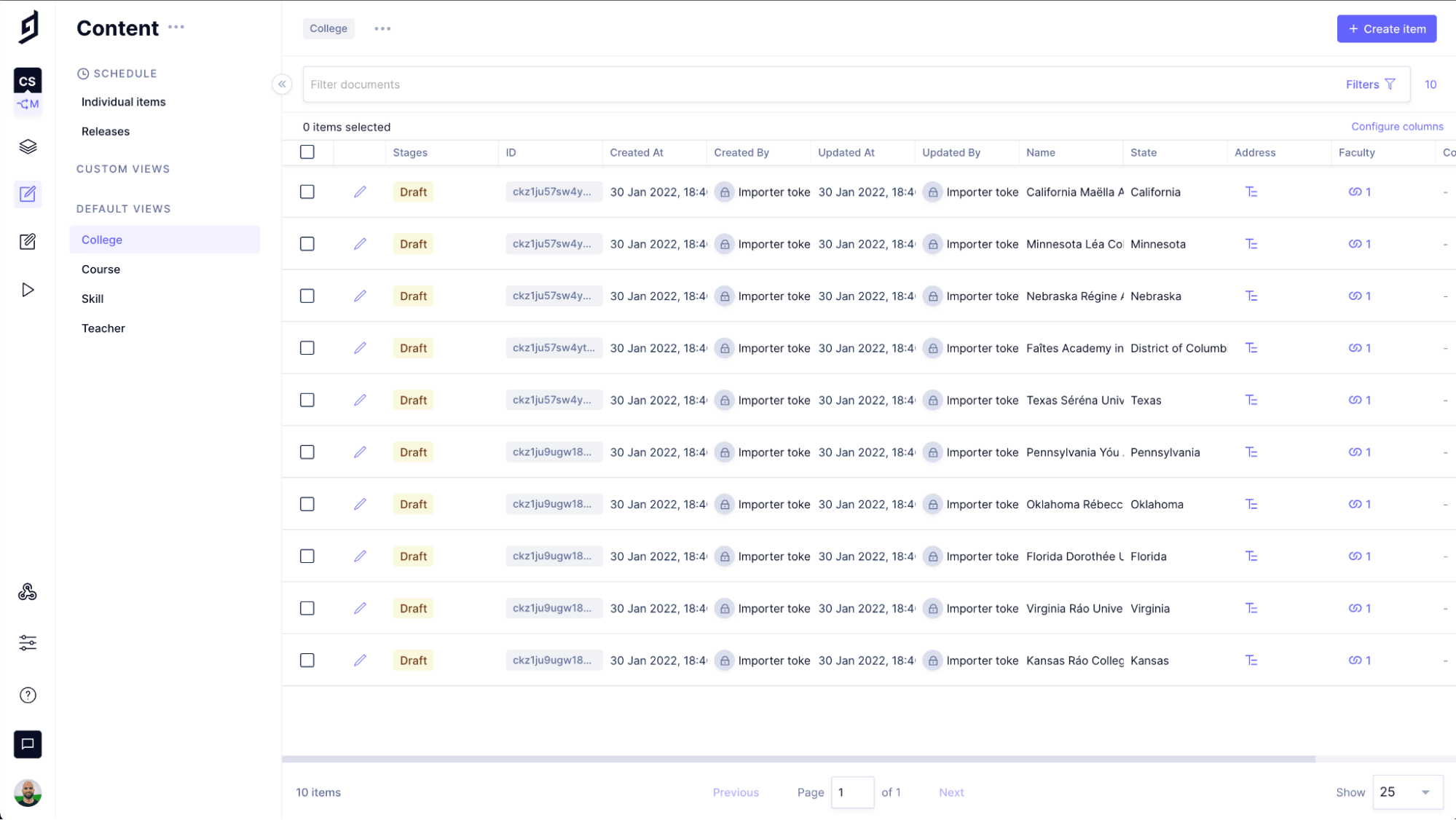
From here, you rinse and repeat for the remaining CSVs. The mutation will differ, but the process is the same!
RecapAnchor
Each workflow will need to be heavily modified depending on the CSVs you have on hand. The tooling with Retool or other low-code utilities provides onboarding paths for non-technical staff to be able to run data cleaning, importing, and managing.
There are some gotchas to be aware of, including API rate limits, and for batch imports like this, working with some non-official workarounds like creating an “import relation”.
At the end of the day, the better approach lies somewhere in between. Let a developer resource create a serverless function or some other data handling mechanism that executes the manipulation and mappings on a server, and use tools like retool to build the back-end office with a minimal interface to the final transformation. Using the management API in conjunction with the content API creates a tight coupling between schema-driven development and the end need.
But for those that truly need batch importing of CSVs in a low-code context, and there are some use-cases where there is no other way around it, I hope this tutorial provided the tooling you needed to empower you in handling your content import needs.
Thanks for reading!

